

- 9 mins
Con el uso de la tecnología y el manejo de datos cada vez más frecuente en las organizaciones, también han aparecido obstáculos por superar, sobre todo si las empresas desean competir en un entorno que cada vez está más digitalizado, mismo donde los procesos y flujos de trabajo funcionan a partir de la información.
Sumado al avance tecnológico, aparecen nuevas herramientas para la mejora constante y que facilitan procesos manuales, y es aquí donde muchos departamentos pueden encontrar un talón de Aquiles, pues el error humano es natural, sin embargo, en la actualidad tiene un costo empresarial, tanto en tiempo como en el área financiera.
La mente y capacidad de una persona podría gestionar sin inconveniente el registro o la inserción de centenas de datos, pero ¿podría gestionar miles o millones en poco tiempo y sin equivocarse? Es una tarea que a menor tiempo se vuelve más compleja y los errores o discrepancias surgen con más facilidad.
La suma de errores que podrían surgir en un proceso de Data Entry pueden resultar en grandes consecuencias, mismas que tienen solución si tú o tu equipo de trabajo cuenta con las herramientas precisas y el conocimiento para resolver desde problemas comunes como typos, llenado erróneo de algunos campos o que éstos estén vacíos, hasta algo más complejo como hasta duplicados o formatos erróneos.
¿Cómo reparar errores en la calidad de datos?
Si durante la captura de datos resuelves problemas fácilmente significa que vas por el camino correcto hacia la calidad de datos, sin embargo, si tuvieras que gestionar o mejorar un proceso relacionado, este podría afrontarse a partir de 2 caminos, el de la prevención y el de la corrección.
- Prevención: Este camino implica recolectar todos los datos útiles disponibles, así solo se procesarán los que en realidad tienen un valor y aquellos que no lo tengan se descartan o eliminan. Además, si esto viene acompañado de un proceso de validación de información, se asegura un trabajo con posibilidades mínimas de presentar errores y en consecuencia una óptima calidad de datos.
- Corrección: Este enfoque tiene como primer objetivo la identificación de la información, es decir, el perfilado de datos, para continuar con su limpieza. Lo anterior permitirá tener un panorama claro de la disponibilidad de valores y así saber con exactitud qué es lo que debe ser corregido.
Seguir estas dos directrices ayuda a reparar errores que son más frecuentes de lo que imaginamos y mencionamos anteriormente, como los typos o vaciado de información. No obstante, ¿qué hacer cuando surgen fallas que podrían percibirse más difíciles de reparar.
1. Deduplicación de datos
Los datos duplicados pueden provenir de una intención humana o una mala gestión. En el primer caso, puede que algún cliente se registre ante el mismo centro de datos con su primer nombre y en una segunda ocasión con el segundo, y aunque el apellido es el mismo, ya hay un duplicado; en el segundo caso, el duplicado puede ser la consecuencia de una fusión de fuentes.
Lo anterior se puede solucionar a partir de un método de deduplicación de datos o Data Deduplication, que no es más que un proceso para quitar aquellos datos repetidos que están alojados en un solo sistema de almacenamiento. A su vez, éste asegura que la información esté organizada pues no hay margen a que haya un doble registro de un correo electrónico o nombre, por ejemplo.
¿Qué medidas debes tomar ante la duplicación de datos?
- Hacer uso del perfilado de datos para determinar qué información requiere de la deduplicación.
- Estandarizar los campos y estructuras de las bases de datos con el fin de homogeneizar la mayoría de la información, y así facilitar la eliminación de errores por formato o valor de las bases de datos.
- Mapear los campos que recogen los mismos datos. Esto puede suceder con direcciones, números telefónicos o correos electrónicos.
- Elegir una herramienta de detección de coincidencias dependiendo tus necesidades. Una puede ser la resolución de entidad, que identifica los datos registrados desde una o más fuentes y los vincula en uno solo.1
De acuerdo con American Health Information Management Association reparar duplicados tiene un costo de entre 10 y 20 dólares por cada uno.
2. Unificación de formatos
La diferencia e inconsistencia entre formatos es otro de los inconvenientes al momento de querer brindarle calidad a los datos con los que trabaja una empresa. Por ejemplo, una fecha puede registrarse de diferentes maneras, (día, mes, año-año, mes, día-con letra o número) por lo tanto, si una se diferencia en formato del común denominador, la secuencia de flujos y errores de datos podría derivar en algo más grave que requiera más detalle para repararlo.
La manera de evitar un problema como este involucra a los embajadores de datos, quienes deberán de establecer un formato único en el cual se trabajara para determinado proyecto. Además, otra camino a seguir es un proceso de preparación de datos, donde se revisan y unifican los formatos previo a su uso.
Nunca está de más una revisión manual, sin embargo, se debe considerar la cantidad de información a procesar.
3. Información completa
El análisis de datos no tiene forma de completarse si de inicio la información está incompleta o existen campos que no cuentan con sus valores correspondientes. La falta de información es otro de los inconvenientes con el que se encuentran los analistas.
Los datos faltantes se pueden dar por intencionalidad, por ejemplo, un usuario no respondió alguna pregunta de una encuesta y por ende el campo lucirá vacío, no obstante también existen otros factores como fallas en el sistema al momento de recopilar cifras. Si bien no hay forma de parchar una problemática como la falta de información, sí hay 2 formas de manejarlo de acuerdo con Free Code Camp:
- Supresión: En esta técnica, al detectarse el campo faltante, elimina el registro de los valores o categorías que están vacías o incompletas. Su desventaja es la posible pérdida de datos por lo que se recomienda su uso cuando la escasez de información es mayor a la disponible.
- Imputación: Consiste en reemplazar información a partir de valores ya obtenidos, y así completar un análisis. Puede ejecutarse a partir de un modelo predictivo o aplicación de variables.
4. Datos huérfanos
El término de huérfano se puede explicar a partir de que un dato depende o está conectado a otro, ya sea en una fila, columna o en otro sistema, y si uno de los dos falta es cuando se le puede denominar así. Por ejemplo, la información de un cliente, en un lugar está su nombre pero en el apartado de cuenta o correo no hay registro o viceversa.
Al tener un dato huérfano hay 2 consecuencias claras, o se está desperdiciando espacio o gestionando información que no es 100% útil.
Si continúas con un flujo o proceso con datos huérfanos es probable que haya errores y tu información sea inexacta. Por lo anterior, es importante revisar en un paso previo que esto no suceda en tus bases de datos pues el movimiento posterior, como la limpieza, podría consumir más tiempo.
5. Silos de datos
Tener información resguardada en silos de datos también forma parte de un problema de calidad, pues estos no permiten la unificación de los mismos en una sola fuente. Al haber fragmentación, un análisis no puede estar completo pues no hay insights confiables, y así las decisiones de negocio no están sustentadas, lo que puede afectar áreas operativas y financieras.
Un buen proyecto a construir ante los datos fragmentados es el uso de las soluciones de extracción, transformación y carga de datos (ETL) que actualmente ofrece el mercado tecnológico.
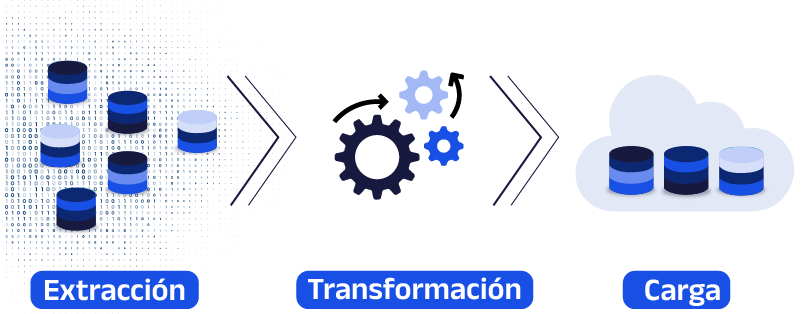
Una solución competente te puede ofrecer la integración de datos y metadatos en grandes volúmenes y así facilitar más procesos relacionados como lo son el perfilado, la limpieza, integración descubrimiento, etc.
6. Tipos de validación de datos
Ante el uso de datos en la actualidad, analizarlos sin que pasen por un proceso de validación o cumplimiento, donde se involucren otras estrategias como la limpieza o el perfilado, representa un riesgo, pues no habrá un punto de medición para saber si la información tiene las características suficientes o los atributos necesarios para ser útiles.
Por lo anterior, aplicar reglas de validación de datos en el proceso de ETL es necesario al interior de las organizaciones para evaluar si estos se encuentran listos para ser procesados. Existe una serie de tipos de validación de datos2 que deben de aplicarse, mismos que garantizan un camino más seguro hacia las decisiones de negocio.
- Tipo: Verifica si el tipo de dato ingresado a un campo es correcto. Por ejemplo, números o letras.
- Códigos: Revisa que un dato sea correcto a partir de una lista de validación ya establecida, puede ser la lada telefónica o el código postal de un país.
- Rango: Rectifica que la información recabada cumpla con un rango establecido, por decirlo, los meses, que no debe rebasar el número 12.
- Formato: Los datos con formatos predeterminados deben ajustarse a este, el orden de las fechas es un ejemplo (dd/mm/aaaa o aaaa/mm/dd).
- Consistencia: Sirve para respetar el orden en determinados procesos, como que una entrega no puede estar fechada antes del envío de un producto.
- Unicidad: Se cerciora que no existan datos que sistemáticamente no deben estar duplicados, un correo electrónico o el número de matrícula de un auto.
- Existencia: Tiene como objetivo detectar que no se omita alguna información. En el caso de un formulario ningún campo debe quedar vacío.
- Longitud: Contempla que a cierta información no le sobre o le falte algún dato. El mejor prototipo son los caracteres de las contraseñas.
- Ratificación: Se encarga de reducir errores al punto de consultar si la información registrada cumple con valores establecidos, tal es el caso de registrar días de la semana o meses, donde el primero no debe rebasar 7 o el segundo no debe pasar de los 12.
7. Soluciones en calidad de datos
Alcanzar la calidad de datos deseada se puede convertir en un camino más fácil de recorrer si se cuenta con una herramienta que brinde la solución adecuada para la gestión de grandes volúmenes de datos.
Estas te otorgan las funcionalidades necesarias para desempeñar procesos como el perfilado o limpieza, mismos que te llevarán a alcanzar calidad en tus flujos de trabajo, optimizarlos y reducir el margen de error por la intervención humana.
Nuestra solución
En Arkon Data contamos con las soluciones precisas para que tu compañía alcance el nivel de calidad de datos que deseas en tus procesos internos y así potencializar tu información al punto de que cada dato se convierta en un activo e impulse el crecimiento de la organización.
¿Estás listo para aprovechar el valor de tus datos?
1 Sonal Goyal, 2021.
2 Manisha Jena, 2022.

