

- Machine Learning
- 8 mins
What is the scope of data and how far can I go with it? Perhaps it is a question that you and your team have asked yourselves to propose new projects or your leaders have questioned you. The answer depends on how far you want to go and under what standards.
Machine learning is one of the objectives that an area, department, or organization can pursue However, in order to reach that goal, certain steps must first be optimized, and these in turn must be carried out in compliance with certain guidelines.
One of those steps is Data Quality, essential for a machine-learning project to achieve success. Why? The design and construction of a plan with such technological and informative impact can be analyzed in a simple way if you imagine that you are an authentic chef.
You are an ace in the kitchen and you decide to make a dish that you have already mastered and are ready to prepare it. To start, you ensure having a cooking area with certain characteristics, utensils, and most importantly, the right ingredients.
By having what is necessary, plus your knowledge, the meal will be ready to taste and you will be able to improve it based on your experience. But what would happen if your ingredients are rotten? The meal will definitely not be as delicious, no matter how expert you are and how many seasonings you add; it even becomes the risk of disease if you eat it.
The same happens with Machine Learning and data; if your ingredients, which are data, are not reliable, precise and do not have properties that accomplish certain requirements, even if you have the perfect team, the final project will be just as inconsistent or will not work, a situation that translates into a time and resources lost.
If a machine learning project fails, data scans, maps of trends or patterns, and projections will be inaccurate; which will cause that business decision doesn’t have sufficient bases to be executed.
Influence and performance of Data Quality on machine learning models
It is a reality that with time, technologies and tools such as Artificial Intelligence and Machine Learning are becoming more consolidated in the market in order to promote the development of multiple industries.
Speaking of machine learning, it is important to underline that due to the nature of its objectives, such as analysis or projections, it requires frequent development to improve its response speed or perfection of forecasts, and this is only achievable if it has Data Quality. The relationship between the accuracy of the information and the progress of a learning model is simultaneous since the latter will only be as good as the data.
One more element to consider in this technological chain is the algorithm, which feeds learning models from data patterns. That is why it is relevant to talk about the role of quality in areas like machine learning.
How does bad data affect a machine learning process? There are different ways in which information alters a learning model:
- Poor processes: If the reference data to detect patterns contains errors or inaccurate values, it will be more difficult for the testing stage to function properly.
- Incomplete analysis: A ML model requires a volume of data, with more information that exists the analysis will be better, and if it does not have information, its task will be inefficient.
- Predictive alteration: The data misbehavior in a learning process can also be undesired, which affects the understanding of how to predict.
Data Quality directly impacts how a machine learning model can perform or transcend, so you must address its issues in detail.
Data Quality role in a machine learning process
Applying a machine learning model is not simple but is possible if you follow certain steps to guarantee that it will be executed with standards regarding data quality with which you will work, on this occasion we will divide it into 7:
- Profile your data: The discovery of information will be an indicator of what you have available to start exploiting your data.
- Establish guarantees: Once you know the data available, establish guidelines to segment what does and does not accomplish quality standards.
- Validate the quality: Reviewing data quality should be an ongoing process, do it constantly to minimize errors.
- Clean and transform: Data Cleansing will help you rule out duplicates, errors, and inconsistencies.
- Choose correctly: The performance of a machine learning model is directly related to the available data; choose the one that aligns with your resources.
- Boost your knowledge: Apply the appropriate engineering to potentiate, learn, and forecast through data.
- Test and apply: Before running a model, test it down to the smallest detail. This way you will know if it is ready or not to apply.
Ensuring that data has good quality has positive effects, as shown 7 points above, but beyond them, there are essential actions that give meaning to data quality. We specify it below.
How to maintain adequate data quality?
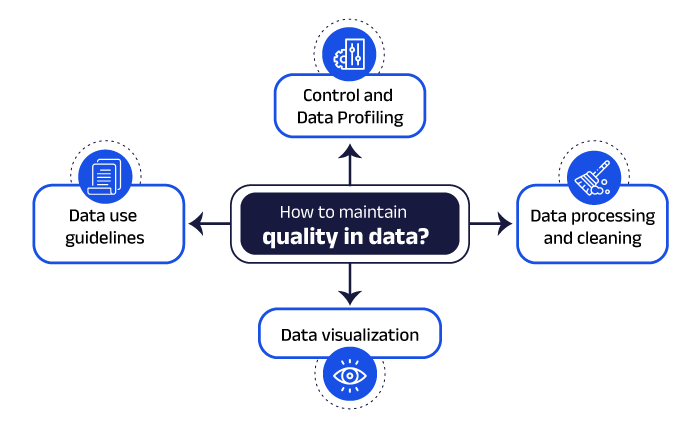
Throughout this blog, we have shared the impact of Data Quality in a machine learning model, but if you are wondering how to maintain the quality, the best practices are described below, which are essential to set the strategy of ML.
Rigorous control and data profiling
One of the initial errors that could be made is not controlling the entry of information to a company, it can come from different sources that don´t have control or even from third parties. A practical and effective data profiling tool that detects patterns, formats, values, and inconsistencies is crucial1.
Data processing and cleaning
Having previously set a cleaning process that standardizes the data, in addition to improving performance, suppresses risks or inappropriate behaviors in the machine learning model.
Data Visualization
Having Data Visualization helps better understand the patterns, trends, and performance of a machine learning model.
Data Usage Guidelines
Establishing policies or rules for the use of a database favors filtering for their subsequent collection and usability.
Data Quality drives the machine learning strategy, however, the selection of information and sections of a database acts as a filter to determine what an algorithm works with. With this, it is necessary to know in depth the role of these characteristics in processes.
The role of feature engineering in Machine Learning
Feature engineering is an element that gives life to a machine learning process, it is responsible for extracting and using the data to make the algorithms work effectively. With this premise, there are 3 steps that involve feature engineering2:
- Selection of characteristics: it is useful to reduce the variables or discard characteristics that do not contribute enough to the modeling.
- Feature extraction: This step aims to combine existing features with new ones to give the algorithm a boost.
- Creation of new features: Adopting new features is also possible once data is collected, thus expanding the panorama of your information.
The 3 characteristics, despite having an independent process, cannot ignore Data Quality since both processes are co-dependent.
Data monitoring in Machine Learning
Finally, the growth of Machine Learning opens many doors both for customer experiences and for a competitive improvement of companies. For this, maintaining high data quality becomes more relevant.
It might be thought that when the data has been used for the training phase or for a machine learning model creation, we should forget about it, however, taking care of its quality is still important, both in the intermediate phase and the deployment or execution. To comply with the latter, we need to put special attention to serious failures that can diminish development in the technological project.
The failures to which we refer are:
- Cardinality shifts. It refers to the miscategorization of data, for example, if you are a tire seller, you cannot give the model data for both motorcycles and cars, as this would produce incorrect forecasts about their consumption.
- Data discrepancy. In order not to have results with discrepancies based on differences between the model and data, work must be done on the information reliability and, if there were changes in it, align the data.
- Missing data: Can you imagine during a machine learning process, missing data is detected? That could alter all the work and the solution is not restarting the process, but detecting where the missing field is or finding variables such as the mean, the average, or some other metric.
- Data out of range: It refers to the similarity level of data provided to the model and the data from the database. For example, in a sales year such as 2010, the base does not provide sales from 2011.
Conclusion
The business world and technological advances every day require data, and if this is the way to go, we must ensure that the treatment seeks perfection. One way to do it is through quality treatment because this process will benefit and contribute to the implementation of technologies such as Artificial Intelligence and Machine Learning.
At Arkon Data we look for quality, which we obtain from strategies such as data cleaning, standardization, and validation. We have the capacity for companies to obtain solutions in the management of the high volume of data and we provide support for those who wish to adopt new technologies to make business decisions and evolve their companies.

1 Stephanie Shen, 2019.
2 Sanidhya Agrawal, 2020.
