

- ETL Process
- Data Quality
- 9 mins
Organizations have encountered obstacles to overcome with the increasing use of technology and data management, especially when they want to compete in an increasingly digitized environment, and even where the processes and workflows develop themselves thanks to information.
In addition to technological advances, new tools facilitate manual processes, becoming an Achilles’ heel for many departments since human error is natural, but it has a cost, both in time and in money.
The mind and capacity of a person could easily manage the register or insertion of enough data, but could it manage a million pieces of information in a short time without making mistakes? It is a task that becomes more and more complex and errors or discrepancies arise easily.
The cluster of errors that could arise in a Data Entry process can aim in serious consequences, the same ones that have a solution if you or your teamwork have the precise tools and knowledge to solve common problems such as typos, erroneous filling of fields, even when dealing with something more complex like duplicates or erroneous formats.
How to repair data quality issues?
If you can manage problems when capturing data thanks to your experience, it means that you know the right path to Data Quality. However, if you had to improve a process related to quality, you could be faced with 2 options, prevention, and correction.
- Prevention: This way implies collecting all available and useful data, so only those that are valuable will be processed, and those that do not are discarded or eliminated. In addition, if this is linked with an information validation process, you obtain a project with minimal errors and consequently optimal data quality.
- Correction: This approach has as its main information identification to continue with cleansing, e.g., Data Profiling. This will allow a clear overview of the availability of values and therefore knowing exactly what must be corrected.
Following these two guidelines helps to repair errors that are more frequent than you can imagine, such as typos or information lack. However, what can you do when complex failures arise?
1. Data Deduplication
Data Duplication can come from human intent or mismanagement. In the first case, a client may register in the same data center with a first name and on a second occasion with the last, and although the last name is the same, there is already duplicated information; in the second case, the duplicate may be the consequence of a merge of sources.
The aforementioned can be solved using Data Deduplication, which is a process to remove repeated data that is housed in a single storage system. Similarly, it ensures organized information since there is no room for double registration such as in an email or name.
What measures should you take when faced with data duplication?
- Use of Data Profiling to determine what information requires deduplication.
- Standardize the fields and structures of the databases in order to homogenize the majority of the information, and thus facilitate the elimination of errors by format or value in the databases.
- Map the fields that collect the same data. This can happen with addresses, phone numbers, or emails.
- Choose a tool depending on your needs. One might be entity resolution, which identifies recorded data from one or more sources and links them into one.1
According to the American Health Information Management Association, solving data duplicated costs between $10 and $20.
2. Formats unification
The difference and inconsistency between formats are other drawbacks when wanting to provide quality to data companies. For example, a date can be registered in different ways, (day, month, year-year, month, day-with letter or number) therefore, if one differs in format from generality, the sequence of flows and errors of data could lead to something more serious that requires specific resources to repair.
Data ambassadors are actors who can avoid problems like that, and who must establish a format for a project. In addition, another path to follow is a data preparation process where the formats are reviewed and unified before their use.
A manual review never hurts, however, the amount of information to be processed must be considered.
3. Incomplete information
There is no way to complete a data analysis if the information is incomplete or if there are fields that do not have their corresponding values. The lack of information is another issue for analysts.
Missing data can occur intentionally, for example, a user did not answer a question in a survey and therefore the field will look empty. However, there are other factors such as system failures when collecting data. There is no way to patch an issue like missing data, but there are 2 possible solutions to handle it according to Free Code Camp:
- Suppression: When the missing field is detected, this technique deletes the record of the values or categories that are empty or incomplete. Its disadvantage is the possible loss of data. It’s recommended when the scarcity of information is greater than that available.
- Imputation: It consists of replacing information from values obtained to complete an analysis. It can be executed from a predictive model or application of variables.
4. Orphaned data
The orphan concept can be explained by the fact that a piece of data depends on or is connected to other data, whether in a row, column, or with another system. For example, information about a customer remains in one place, but in the account or mail section, therefore there is no record, and vice versa.
When having orphaned data there are 2 clear consequences, either space is being wasted or information that is not 100% useful is being managed.
If you continue with a flow or process with orphaned data, there will likely be errors and your information will be inaccurate. Consequently, it is important to check in a previous step that this does not happen in your databases since the subsequent movement, such as cleaning, could waste more time.
5. Data silos
Another Data Quality problem is having information stored in data silos since these do not allow unification in a single source. As there is fragmentation, an analysis cannot be complete because there are no reliable insights, and thus business decisions are not supported, which can affect operational and financial areas.
A good project to face data fragmentation is the use of data solutions like ETL (Extract, Transform, and Load) which are currently offered by the technology market.
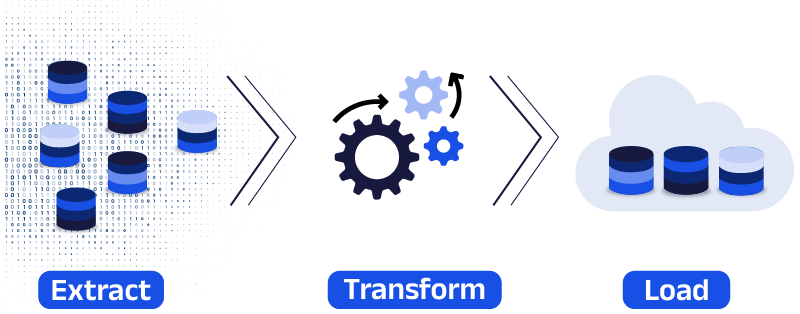
A competitive solution can offer you data and metadata integration in volumes to facilitate more related processes such as profiling, cleaning, discovery integration, etc.
6. Lack of validation rules
Analyzing data without going through a validation or compliance process, where other strategies such as cleaning or profiling are involved, represents a risk since there will not be a measurement control to know if the information has enough features or attributes to be useful.
Hence, applying data validation rules in the ETL process is necessary within organizations to assess whether they are ready to be processed or not. Some types of data2 validation must be applied, which guarantees a safer path to business decisions.
- Type: It verifies if the type of data entered in a field is correct. For example, numbers or letters.
- Codes: It checks that a piece of information is correct from an established validation list, it can be the phone number or the zip code.
- Range: It rectifies that the information collected complies with an established range. For example, months, which should not exceed the number 12.
- Format: Data with default formats must be aligned, the order of the dates is an example. (dd/mm/yyyy or yyyy/mm/dd).
- Consistency: It serves to follow the order in certain processes, such as that a delivery cannot be dated before the shipment of a product.
- Uniqueness: It makes sure that there is no data that should not be duplicated, an email or the car registration number.
- Existence: Its objective is to detect that information is not omitted. In the case of a form, no one field can be empty.
- Length: It contemplates that certain information does not have excess or is missing some data. The best example is the password characters.
- Ratification: It is in charge of reducing errors and consulting if the registered information complies with established values, such is the case of registering days of the week or months, where the first must not exceed 7 or the second must not exceed 12.
7. Data Quality solutions
Achieving data quality can become an easier path to walk if you have a tool that provides the right solution for managing large data volumes.
These tools can provide the necessary functionalities to carry out processes such as profiling or cleaning, which will lead you to achieve quality in your workflows, optimize them and reduce the margin of error due to human intervention.
Our solution
At Arkon Data we have the precise solutions for your company to achieve the level of data quality you want in your internal processes. As a result, you can boost your information to transform each piece of data into an asset and drive the growth of your organization.
With our tools you will be able to:
- Validate data as it is collected so that it meets internal quality rules.
- Clean up existing duplicate, incorrect, or differently formatted records of data.
- Analyze data and get an overview of its characteristics such as the distribution of values.
- Automate data quality tasks and processes to increase efficiency and reduce human error.
Are you ready to escalate the value of your data?
1 Sonal Goyal, 2021
2 Manisha Jena, 2022.

